2枚のとは違うのか?
大した違いはないんじゃないだろうか。結局のところ回帰レイヤーは自分の出力が自分に返ってくるのでNユニットの2枚のLSTMでできることは2Nユニットの1枚のLSTMでだいたい可能である。(返ってくるまでに1ステップの時間がかかるので全く同じというわけではないが。)
同じユニット数だともちろん2枚の方が色々なキャパシティが上がるとは思うが、同時に回帰レイヤーのトレーニングは時間ステップを遡りながら行うので重くなりがちである。実際に1枚のものと2枚のものではだいたい3割程度、1ステップの学習速度に違いが出る。
一方シンプルな系(Atariのゲーム)で学習成果を試したところ、1枚のものも2枚のものもだいたい同じステップ数だと同程度のパフォーマンスになる。だとすると1ステップあたりの学習が早い1枚のものの方が有利だということだ。もちろん複雑な系の場合はどうなるか不明である。
最初2枚のものから始めたのは、PyTorchのデフォルトの値が2枚だったからで、特に深い理由はなかった。その後、OpenAIのDota2のAIがLSTM1枚で行われていることなどを知って、1枚の方がよいのではないかと思うようになった。
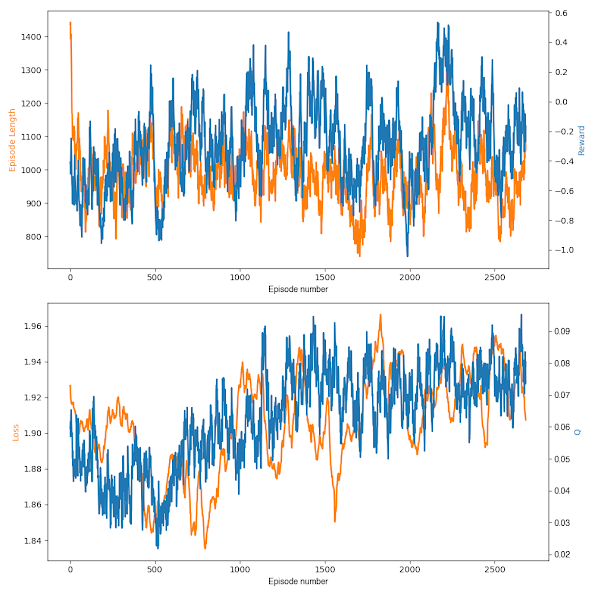
で、1枚のものと2枚のもの、試したところ実際どちらがよかったのかという話だが、残念ながら結論が出なかった。次の2枚の図を見ていただきたい。


上が1枚のもので、下が2枚のものである。枚数以外はほぼ同じ条件である。2枚のものはゴールラインの0.5を越えたので止めたが、1枚のものは越えなかった。Rewardだけ見ると勿論2枚の方が成績がよいのだが、このあたりの数値はノイズが大きくもある。Lossの値を見ると確かに1枚のものの方が早く収束しているし、値も低く保たれている。Qの最終値も大きいし、何なら先に0に到達したのは1枚のものの方だ。どちらが先に0.5に到達したかというのは、偶然性の寄与するところが大きいように思われる。
問題はこの後だった。2枚にしようかな、と思ってその先に進んだ結果、途中で成長が止まってしまったのだ。次の図はLv2をクリアした2枚のモデルでLv3に進んだ結果である。